随便写写Kafka,并且大俗特俗的从安装操作开始写起。
Kafka 的安装
首先要有 jdk! 其次要有 zookeeper!不过kafka的发行版压缩包中,已经集成了zookeeper。 从官网下载最新版的Kafka,解压后就可以直接使用了。
启动zookeeper:
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
启动Kafka
bin/kafka-server-start.sh -daemon config/server.properties
这样一个单节点的Kafka就启动了。早期的版本启动的时候还需要使用 nohup 来放到后台。现在只需要带 -daemon 参数了。
Kafka 的操作
只列几个常用的命令,更多的命令可以到官网上去翻文档。
创建topic
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic etl-kafka --partitions 24 --replication-factor 1
列出所有的topic
bin/kafka-topics.sh --zookeeper localhost:2181 --list
查看topic信息
bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic etl-kafka
测试发送消息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic etl-kafka
测试接受消息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic etl-kafka --from-beginning
以上是最常用的命令,此外还有些管理 topic 的命令,如
修改 topic
bin/kafka-topics.sh --zookeeper zk_host:port/chroot --alter --topic my_topic_name --partitions 40
删除 topic
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic my_topic_name
还有关于集群管理、consumer管理、数据平衡等的命令。
Kafka 的设计
Topic
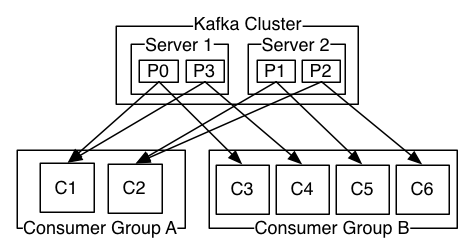
kakfa 启动后,首先要创建Topic,才能接收数据。Topic 可以看作是一个个目录,用来存放消息。每个Topic都可以有多个 producer,consumer。
Partition
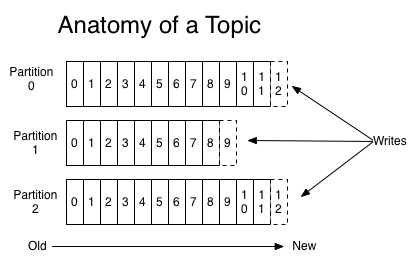
Topic 中的消息是分区存放的,具体有多少个区,可以在创建的时候指定。当 producer 在向 Kafka 中写入数据的时候,通过指定的分区ID、或者计算出来的分区ID,将消息放入各个分区中。分区是有序的,当 producer 向分区写入消息时,每条记录都会有获得一个唯一的编号 offset。
如下图所示
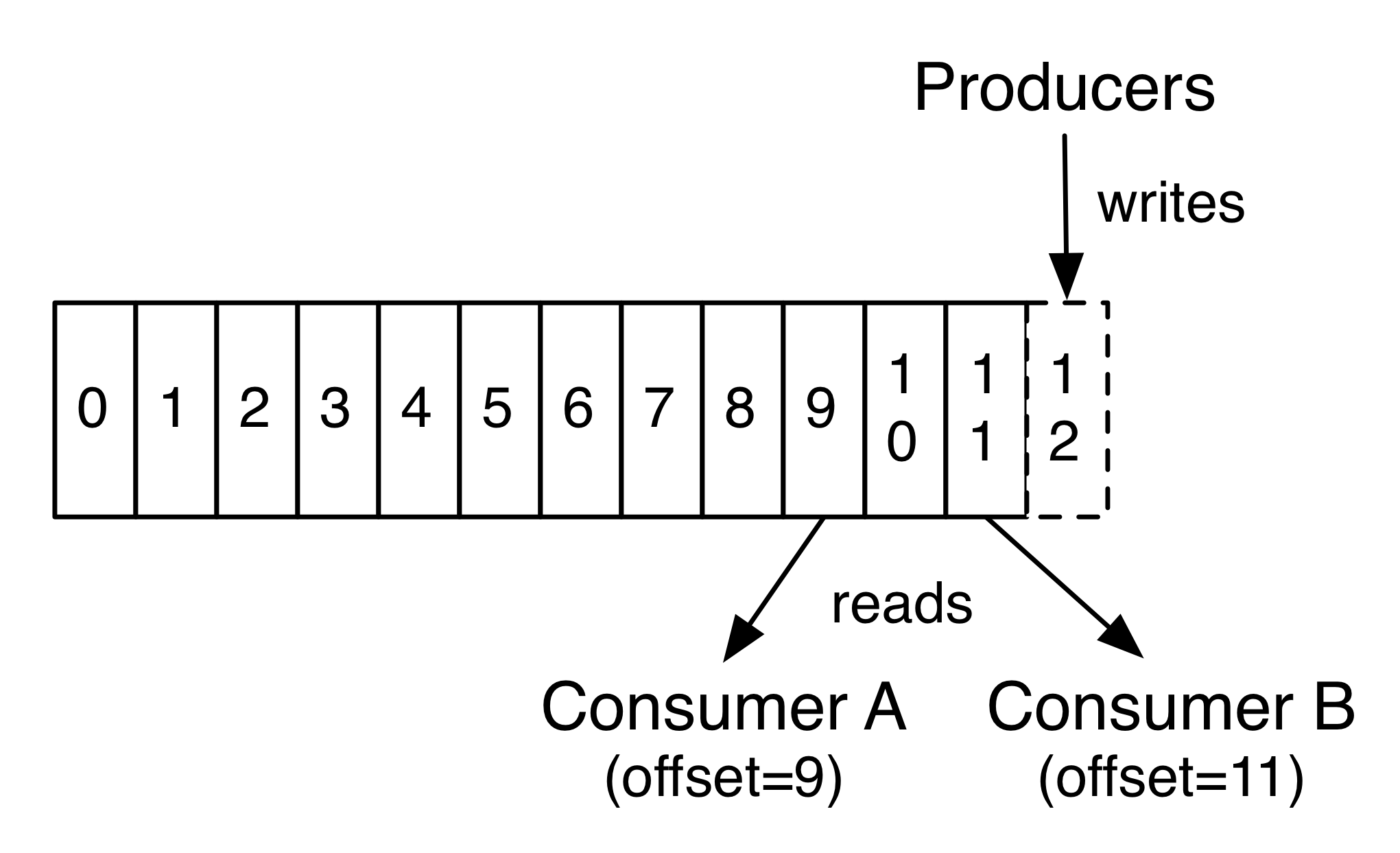
当 consumer 获取消息时,就可以根据分区ID,offset 去请求数据,如下图
集群
集群的信息由 zookeeper 来维护。节点信息、topic信息 等都会保存在zookeeper上。
分区是散布在集群中的多个节点上的,并且在创建Topic时,通过设置 replication 来提高可用性。
如果replication 设为1,表示没有复制集,数据只有一份。这种情况下,一个分区只会存在在一个节点上,换句话说,就是分区在整个集群中是唯一的。如果节点不可用,这个节点上所有的分区就都不可用了。
如果replication 设为2,表示有一个复制集。这种情况下,分区会存在在两个节点上(设置replication的前提是,集群有多个节点,单节点集群无法设置复制集)。其中一个作为 leader ,另一个作为 flower 。leader 负责所有的读写请求,flower负责同步数据。当 leader 不可用的时候,flower 会取代旧 leader 作为新 leader。(非常像raft)
Producer
负责将数据写入 kafka。Kafka 集群不关心消息会被放入哪个分片,这个逻辑由producer来实现。
- 可以根据需要使用round-robin来将消息逐个放入不同的分区;
- 可以根据业务需求将消息放入指定的分区
Consumer
从根本上讲 Kafka 集群不关心消费者如何消费数据。只要 Consumer 知道 Topic、分区ID、offset 就可以发起请求获取数据。这样就带来一个问题 offset 的管理
- 过去 Kafka 是不管 offset 的,一切都由用户来管理。
- 后来为了方便用户,将 offset 保存在zookeeper里,并引入了 consumer group 的概念:一个 group 内的consumer共享一组offset。
- 现在又提供了新的 offset 管理方式:创建一个内部队列用来维护偏移量。
从用户使用角度来讲,由kafka管理 offset 可能是个发展趋势。不过 offset 仍然可以考虑自己管理一份,这样遇到一些异常情况,可以用自己管理的 offset 来消费过去的旧数据。